Introduction
In today’s fast-paced digital landscape, businesses and platforms must be equipped to handle unpredictable traffic patterns and ever-increasing user demands. As online services, especially those in sectors like streaming, e-commerce, and IoT, continue to grow, they face the challenge of maintaining performance while managing operational costs. Effective scaling strategies have become essential to ensure that systems can accommodate traffic spikes during peak times, such as new product launches, live events, or seasonal sales.
In this blog, we explore various scalable architecture designs that leverage modern computing techniques such as auto-scaling, load balancing, caching, and serverless computing. We’ll delve into how asynchronous communication models, message brokers, and distributed systems enhance resilience and throughput, ultimately ensuring high availability and superior user experience. By examining real-world implementations, we aim to provide insights into the strategies that organizations can adopt to build robust, efficient, and scalable infrastructures for their applications. Whether you are an architect, developer, or business leader, this blog offers valuable knowledge to navigate the complexities of scaling in today’s dynamic environment.
Scenario 1
You are designing a scalable architecture for a growing video streaming platform similar to YouTube. The platform initially ran as a monolithic application on a single server but has started experiencing performance issues due to increased traffic.
a) Explain how vertical scaling could temporarily improve the performance of the system. Discuss its limitations in large-scale distributed systems.
b) Describe how horizontal scaling can be introduced into the architecture. Explain how load distribution would occur across multiple servers.
c) In a horizontally scaled architecture, explain how load balancers help maintain availability and prevent server overload.
d) Design a scalable architecture for the platform using the following components:
- Load balancer
- Web servers
- Application servers
- Database layer
Explain how redundancy, caching, and distributed storage could be incorporated to improve scalability and fault tolerance.
[3 + 2 + 2 + 5 = 12 Marks]
Answers:
a) How vertical scaling can temporarily improve performance, and its limitations
Vertical scaling improves performance by increasing the capacity of a single machine, for example by adding more CPU cores, memory, or storage. If a video streaming platform is initially deployed on one server and traffic begins to rise, moving that server to a more powerful machine can reduce CPU bottlenecks, improve memory availability, and support more concurrent requests. This is often the quickest short-term response because the application does not need major architectural redesign. Getting to know Scalability
However, vertical scaling has clear limitations. First, it is bounded by hardware ceilings, since a single machine can only be upgraded up to a certain point. Second, it creates or preserves a single point of failure. If that machine fails, the entire service may become unavailable. Third, it does not fit well with the needs of large-scale distributed platforms where traffic growth is unpredictable and fault tolerance is essential. For such systems, relying only on a bigger machine delays the real solution rather than solving it.
b) How horizontal scaling can be introduced
Horizontal scaling is introduced by adding more machines and distributing workload across them instead of relying on one powerful server. In the case of the video platform, the monolithic single-server deployment can be split into multiple web or application servers behind a traffic distribution layer. Incoming client requests are then spread across several backend nodes. This enables the platform to support more users, more transactions, and larger data volumes while also improving resilience.
Load distribution occurs through a load balancer placed in front of the servers. The load balancer forwards each request to a healthy server instance, which prevents one server from becoming overloaded. This also supports high availability because if one server stops responding, traffic can be redirected to the others.
c) Role of load balancers in availability and overload prevention
A load balancer improves availability by ensuring that requests do not depend on a single backend node. If one server fails or becomes slow, the load balancer routes traffic to healthy nodes. This removes single points of failure at the server layer and helps maintain service continuity.
A load balancer also prevents overload by distributing requests across multiple servers. Instead of allowing all users to hit one machine, it balances the demand across the cluster. In the case of YouTube, NetScaler performs exactly this role by sitting in front of web servers and distributing incoming traffic. This improves availability, protects against individual server failure, and optimises resource utilisation.
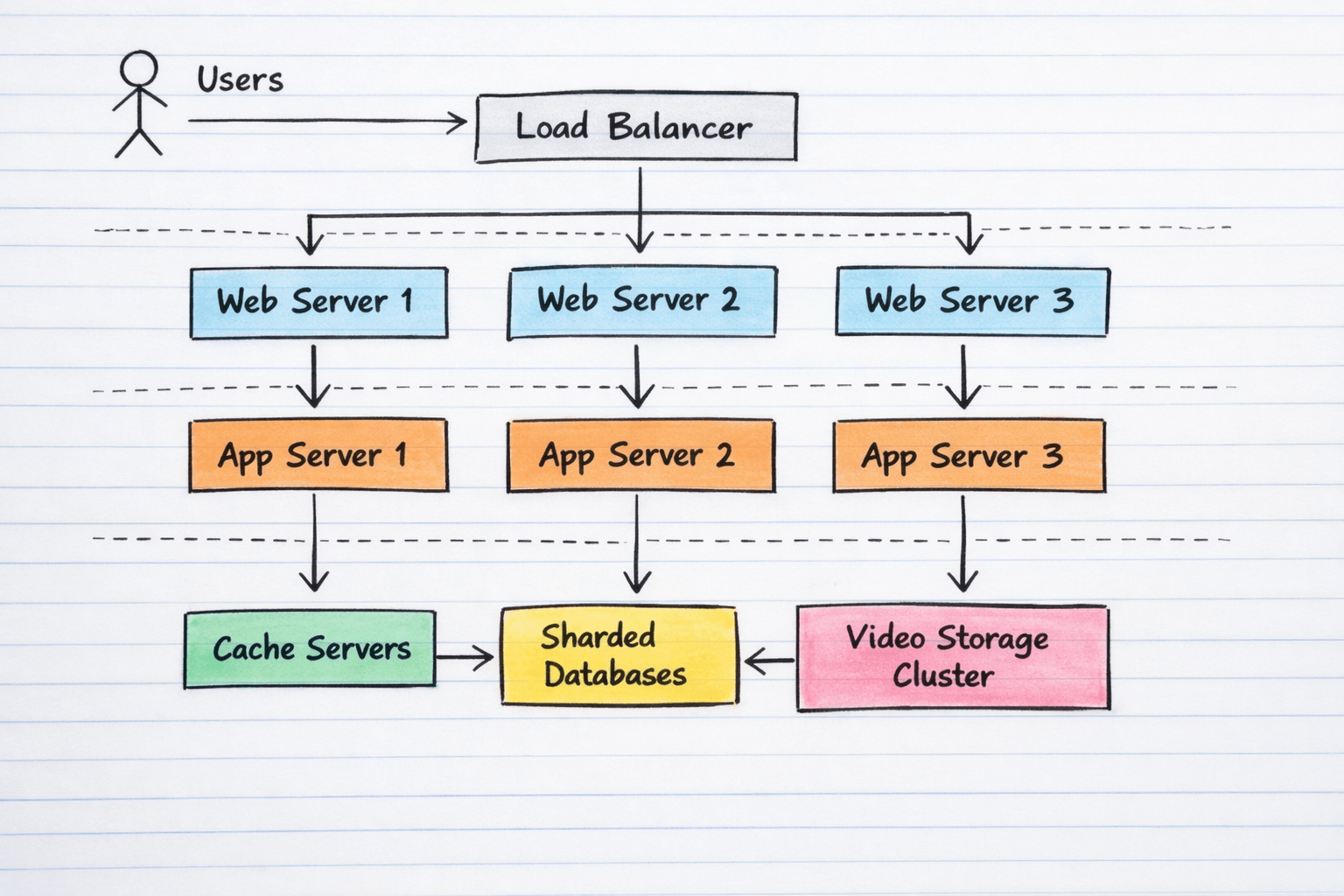
d) A scalable architecture for the platform
A suitable architecture would include a load balancer at the front, followed by multiple web servers, then application servers, and finally a distributed data layer. Clients send requests to the load balancer. The load balancer forwards these requests to one of several web servers. The web server layer handles HTTP communication and forwards business logic requests to application services. The application layer performs user management, metadata handling, upload coordination, and playback logic. The data layer stores video metadata, user records, and content references.
Redundancy should be built into every critical layer. Instead of one web server, there should be several. Instead of one application node, there should be a cluster. Instead of one database instance, there should be replicated and partitioned storage. This avoids single points of failure and improves runtime resilience.
Caching should be used for frequently requested content, especially highly popular videos and metadata lookups. Cached content reduces repeated computation and reduces load on the database and storage layers. Caching is a key principle of scalable systems and popular videos should be replicated and aggressively cached to minimise latency.
Distributed storage should be used for video objects and database data. Large video files can be stored across storage clusters, while metadata can be sharded across database instances. This enables horizontal growth, reduces bottlenecks, and improves fault tolerance. Overall, this architecture is far more scalable than a monolith because individual layers can grow independently, failures are isolated, and traffic can be handled across many nodes.
Scenario 2
A distributed e-commerce platform is experiencing fluctuating traffic patterns. During peak sales events, the system experiences sudden increases in CPU usage and request rates. The platform uses multiple application servers deployed in a distributed cluster.
You are tasked with designing a scaling algorithm that determines the optimal number of servers required to maintain acceptable system performance.
Input parameters:
Current number of servers in the cluster
Average request rate per second
Maximum request handling capacity per server
Target utilisation threshold (for example 70%)
Output:
Recommended number of servers required to handle the workload
Suggestions for improving performance and scalability
Constraints:
The algorithm must ensure that the target utilisation threshold is not exceeded.
The output number of servers must be an integer.
The algorithm should also identify whether horizontal scaling or optimisation techniques (such as caching or load balancing) should be applied.
Task:
Develop a Python function that calculates the required number of servers based on the above parameters. Provide:
- the Python implementation
- explanation of the scaling logic
- assumptions used in the design
- recommendations for improving system scalability
[10 Marks]
Answer 2
Python function
import mathdef calculate_required_servers(current_servers, avg_request_rate, max_capacity_per_server, target_utilisation): """ Calculate the minimum number of servers required so that the average utilisation per server does not exceed the target threshold. Parameters: current_servers (int): current number of servers avg_request_rate (float): current average requests per second max_capacity_per_server (float): maximum requests per second one server can handle target_utilisation (float): desired utilisation threshold as a percentage, e.g. 70 for 70% Returns: tuple: required_servers (int), recommendations (str) """ if current_servers <= 0: raise ValueError("current_servers must be greater than 0") if avg_request_rate < 0: raise ValueError("avg_request_rate cannot be negative") if max_capacity_per_server <= 0: raise ValueError("max_capacity_per_server must be greater than 0") if not (0 < target_utilisation <= 100): raise ValueError("target_utilisation must be between 0 and 100") effective_capacity_per_server = max_capacity_per_server * (target_utilisation / 100.0) required_servers = math.ceil(avg_request_rate / effective_capacity_per_server) if avg_request_rate > 0 else 1 current_total_effective_capacity = current_servers * effective_capacity_per_server utilisation_status = avg_request_rate / current_total_effective_capacity if current_total_effective_capacity > 0 else 0 recommendations = [] if required_servers > current_servers: recommendations.append( f"Scale out horizontally from {current_servers} to {required_servers} servers." ) recommendations.append( "Add or tune load balancing to distribute traffic evenly across all servers." ) elif required_servers < current_servers: recommendations.append( f"The workload can be handled by {required_servers} servers; consider scaling in to reduce cost." ) else: recommendations.append( "Current server count is sufficient for the present workload." ) if utilisation_status > 0.9: recommendations.append( "The system is running close to saturation; caching should be introduced or strengthened." ) recommendations.append( "Monitor response time, throughput, CPU, memory, and I/O to detect bottlenecks early." ) recommendations.append( "If the data tier becomes the bottleneck, consider replication or sharding." ) recommendations.append( "Avoid shared bottlenecks and isolate slow services to prevent cascading latency." ) return required_servers, " ".join(recommendations)
Explanation of the scaling logic
The core idea is to ensure that the average utilisation per server does not exceed the target threshold. Suppose one server can handle 1000 requests per second at maximum, but the design target is to run at 70 percent utilisation for stability and headroom. Then the effective working capacity of one server is treated as 700 requests per second. The total incoming request rate is divided by this effective capacity, and the result is rounded up to the nearest integer. That gives the minimum number of servers required. This approach aligns with the idea that scalable architecture must anticipate growth and avoid saturation under increasing workload.
Assumptions used
This function assumes that all servers are identical, traffic can be distributed evenly, and request load is represented adequately by average request rate. It also assumes that the application tier is the main scaling concern. In real systems, CPU, memory, I/O, network latency, and service dependencies may all affect performance, so server count alone may not solve every problem. Performance degradation can come from CPU bottlenecks, memory pressure, I/O limitations, network latency, or inefficient service dependencies.
Recommendations for improving scalability
If the required server count rises above the current count, horizontal scaling is the preferred strategy because it improves both capacity and fault tolerance. Load balancing should be added or strengthened so workload is distributed efficiently. If traffic repeatedly hits the same data or content, caching should be introduced to reduce pressure on the backend. If the bottleneck is in the data tier rather than the application tier, replication or sharding should be considered. Monitoring should remain continuous so that bottlenecks and slow service dependencies are identified before they cause widespread degradation.
Scenario 3
Modern distributed systems must balance consistency, availability, and partition tolerance.
Using the CAP theorem, analyse the trade-offs that occur when a distributed database system experiences network partition failures. Explain how system architects decide between CP and AP system designs depending on application requirements. Illustrate your answer with real-world examples.
[5 Marks]
Answer 3
When a network partition occurs in a distributed database system, some nodes can no longer communicate with others. At that point, the CAP theorem says the system cannot fully guarantee both consistency and availability at the same time while still tolerating the partition. Since partition tolerance is unavoidable in real distributed systems, the practical decision is between consistency and availability during the partition.
A CP design chooses consistency and partition tolerance. In such a system, if communication between nodes is disrupted, some operations may be rejected or delayed so that the system does not return stale or conflicting data. This is useful where correctness is more important than immediate service. Banking-style transactions are a classic example. It is better to refuse a request temporarily than to return incorrect account information. CP systems sacrifice availability during partitions in order to maintain consistent state.
An AP design chooses availability and partition tolerance. In this case, the system continues responding even if all replicas are not perfectly synchronised. Some reads may return older values, but the service remains available. This is appropriate for systems where continuous access matters more than always seeing the latest write. Social feeds, content platforms, and many large-scale web services often prefer this direction. This trade-off relates to eventual consistency, where replicas may temporarily diverge but eventually converge if no new updates occur.
Architects choose between CP and AP based on application requirements. If stale data is unacceptable, CP is the safer choice. If service continuity matters more and temporary divergence is tolerable, AP is often preferred. Therefore, the CAP theorem is a design framework that forces system architects to decide what kind of failure behaviour is acceptable for the business.
Scenario 4
You are tasked with designing the architecture for a global-scale video sharing platform similar to YouTube.
The platform must support:
- millions of concurrent users
- large-scale video storage
- high availability
- efficient content delivery
Design a scalable architecture that incorporates the following components:
- client–server communication model
- load balancing layer
- web server layer
- video storage cluster
- database sharding
- caching mechanisms for popular videos
Explain:
- How the architecture handles highly popular videos versus less frequently accessed videos
- How sharding improves database scalability
- How clustering improves reliability and throughput
- How the architecture ensures high availability during server failures
Also discuss potential challenges such as bandwidth consumption, replication overhead, and data consistency.
[13 Marks]
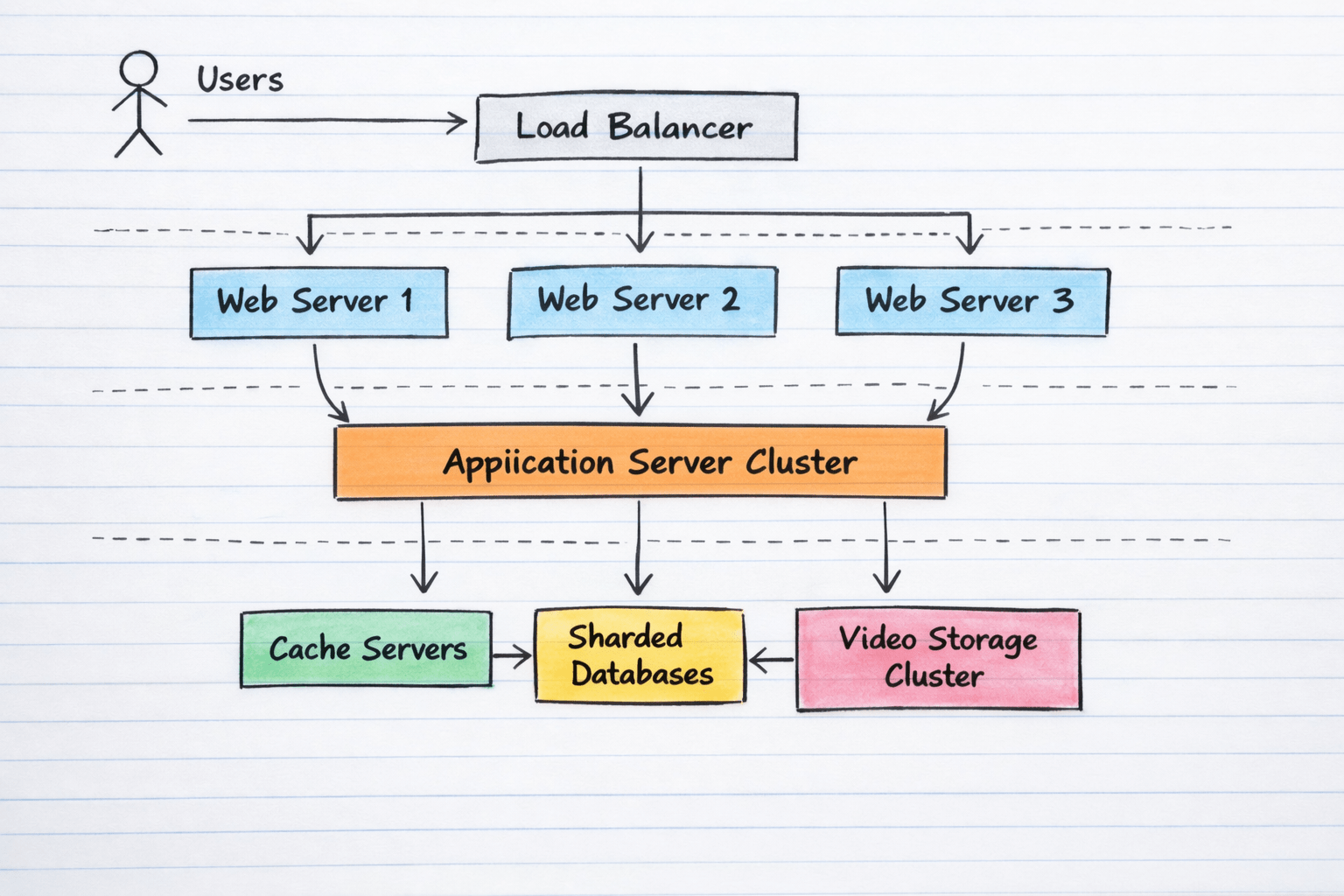
Scalable architecture for a global video-sharing platform
A global video-sharing platform should use a layered client-server architecture. Clients such as mobile apps and browsers send requests to a front-end load balancing layer. The load balancer distributes traffic across multiple web servers. The web servers handle HTTP communication and pass application-specific logic to backend services. Separate video storage clusters hold the large media objects, while the database layer stores metadata such as users, titles, comments, access permissions, and content indexing. The lesson’s YouTube case study follows this overall idea, using NetScaler in front of Apache-based web servers, Python in the application layer, clustered video infrastructure, and a sharded MySQL-based data tier.

1. Handling highly popular versus less frequently accessed videos
Highly popular videos generate concentrated traffic and must be handled differently from less popular videos. Popular videos should be aggressively cached and replicated across multiple servers so that requests can be served quickly with reduced latency and lower pressure on central storage. Less popular videos can be stored with fewer replicas because they are requested less often. This differentiated treatment improves storage efficiency and bandwidth usage while still providing fast access to high-demand content.
2. How sharding improves database scalability
Sharding partitions data across multiple independent database instances, where each shard stores a subset of the total dataset. This reduces the load on any single database, avoids replication bottlenecks, and allows the data tier to scale horizontally. In a global video platform, user data and video metadata can be distributed across shards based on criteria such as region, user identifier, or content category. As demand grows, more shards can be added rather than forcing all traffic through a single database server. YouTube moved beyond simple replication limitations by using shard architecture.

3. How clustering improves reliability and throughput
Clustering means deploying multiple interconnected servers that work together as one logical system. In the video layer, clustering allows many servers to participate in storing and serving content. In the application layer, clustering allows more concurrent requests to be processed in parallel. Throughput increases because work is spread across nodes rather than concentrated on one server. Reliability also improves because failure of one node does not necessarily stop the service. Traffic or storage responsibility can be shifted to other nodes in the cluster. Clustering is a method that supports horizontal scalability and reduces dependence on a single machine.

4. Ensuring high availability during server failures
High availability is achieved through redundancy and fault tolerance mechanisms. Multiple application servers should be deployed so there is no single point of failure. Traffic should be distributed by load balancers that can detect unhealthy servers and stop routing requests to them. Data should be replicated where necessary so that the failure of one node does not destroy service continuity. Geographic distribution can further reduce the impact of regional outages. Backup systems and monitoring should also be in place so failures are detected quickly and recovery actions are possible. These are directly aligned with the lesson’s explanation of availability and high-availability mechanisms.

Challenges in such an architecture
- A major challenge is bandwidth consumption. Video streaming requires continuous transfer of large media files with low latency, so network capacity becomes a central concern.
- Hardware demand and power usage also increase significantly as the platform grows.
- Another challenge is replication overhead. Although replication improves availability and speeds access for popular content, it consumes extra storage and network bandwidth.
- Data consistency is also a challenge, especially when metadata is replicated or distributed across regions.
- Strong consistency gives correctness guarantees but increases coordination cost and latency.
- Eventual consistency improves availability and performance, but temporarily divergent views of data may appear.
These are the core trade-offs that scalable distributed systems must manage.
Scenario 5
A large e-commerce company stores customer and product data in a relational database. As the platform grows, the database becomes a performance bottleneck due to increased query load and data volume.
a) Explain how horizontal partitioning (sharding) can improve scalability in such a system.
b) Compare horizontal partitioning and vertical partitioning, explaining how each affects query performance and system design.
c) The company decides to split the database based on functional domains such as customer information, product catalog, and order management. Explain how functional partitioning works and discuss one benefit and one challenge of this approach.
d) Design a scalable database architecture for this system using sharding across multiple database nodes. Explain how query routing, load distribution, and fault tolerance would operate in the architecture.
[3 + 2 + 2 + 5 = 12 Marks]
a) Horizontal partitioning (Sharding) and scalability
Horizontal partitioning, also known as sharding, divides a large table into multiple smaller tables called shards. Each shard contains a subset of rows from the original dataset and is stored on a separate database server. Instead of storing all records in a single database instance, the data is distributed across several nodes.
This approach improves scalability because queries are distributed across multiple servers instead of a single database machine. When a request arrives, it is routed to the shard containing the relevant data. As a result, the workload is divided among several servers, reducing the load on any individual node.
Sharding also enables horizontal scaling. When data volume and traffic increase, additional shards can be added and data can be distributed among them. This allows the system to grow without requiring a single database server to handle all requests.

b) Horizontal partitioning vs Vertical partitioning
Horizontal partitioning splits data by rows. Each shard contains a subset of records but maintains the same table structure. For example, customer records with IDs 1–10000 may be stored in one shard while IDs 10001–20000 are stored in another. This method is effective for scaling systems with large datasets because requests can be distributed across multiple servers.
Vertical partitioning splits data by columns. Different sets of columns are stored in different tables or databases. Frequently accessed columns may be stored in one partition, while less frequently accessed or larger columns are stored in another. This reduces the amount of data read during queries and can improve I/O efficiency.
The main difference is that horizontal partitioning distributes workload across multiple machines, improving scalability, while vertical partitioning optimizes query performance by reducing the amount of data accessed per request.

c) Functional partitioning
Functional partitioning divides data based on business domains or application functions. Each partition corresponds to a specific functional area of the system.
For example:
- Customer database stores customer profiles and account information
- Product database stores product catalog information
- Order database stores transaction and order history
This approach aligns database structure with business responsibilities and system modules.
Benefit:
Functional partitioning reduces coupling between different system components. Each service or module interacts primarily with its own database, making the architecture easier to scale and maintain.
Challenge:
Queries that require data from multiple functional partitions may become complex. For example, generating a report that combines customer data and order data may require cross-database queries or additional data aggregation logic.

d) Scalable database architecture using sharding
In a scalable architecture using sharding, the database layer consists of multiple database nodes, each responsible for storing a subset of the data.
The architecture typically includes the following components:
- Application servers that receive user requests
- A query routing mechanism that determines which shard contains the requested data
- Multiple database shards storing different subsets of the dataset

When a user request arrives, the application server determines which shard contains the relevant data using a partition key, such as customer ID or region. The request is then forwarded to the appropriate database shard.
Query routing ensures that each query is directed to the correct shard, preventing unnecessary communication with other database nodes.
Load distribution occurs because queries are spread across multiple shards. Instead of one database handling all traffic, each shard processes only the requests relevant to its portion of the dataset.
Fault tolerance can be achieved through replication. Each shard may maintain one or more replica nodes that contain copies of the shard’s data. If a primary shard node fails, one of the replicas can take over, ensuring continued availability.
As the system grows and data volume increases, additional shards can be added to the cluster, allowing the database layer to scale horizontally and support higher workloads.
Scenario 6
A technology company is designing a distributed data analytics platform capable of processing extremely large datasets generated from online transactions and user activity logs.
The system must support large-scale storage and distributed processing.
Input Components:
- Large datasets stored in a distributed file system
- Multiple compute nodes performing parallel processing
- Fault tolerance mechanisms to prevent data loss
Output:
- Processed analytical results derived from large input datasets
Using your understanding of distributed data processing frameworks, develop a Python-style pseudocode implementation that illustrates the MapReduce pattern.
Your answer should include:
- a Map function that processes input key–value pairs
- a Reduce function that aggregates intermediate results
- explanation of how partitioning and parallel processing occur
- assumptions about data distribution and processing
Also explain how combiner and partitioner components help optimise the MapReduce workflow.
[10 Marks]
Python-style pseudocode for MapReduce
The MapReduce model processes large datasets by dividing the workload into two primary phases: Map and Reduce. Multiple map tasks operate in parallel on different portions of the input data, producing intermediate key–value pairs. The reduce phase aggregates these intermediate results to generate the final output.

Below is a simplified Python-style pseudocode implementation.
Map Function
def map_function(key, value): """ key : identifier for the input record value : content of the record """ words = value.split() for word in words: emit(word, 1)
The map function reads input records as key–value pairs. It processes each record and produces intermediate key–value outputs. In this example, each word becomes a key and the value 1 represents a count.
Reduce Function
def reduce_function(key, values): """ key : intermediate key (e.g., word) values : list of counts associated with the key """ total = 0 for value in values: total += value emit(key, total)
The reduce function receives all intermediate values associated with the same key and aggregates them. In this example, it calculates the total count for each word.
How partitioning and parallel processing occur
The input dataset is divided into multiple blocks, and each block is processed by a separate mapper running on a different node. This enables parallel processing, allowing the system to analyse very large datasets efficiently.
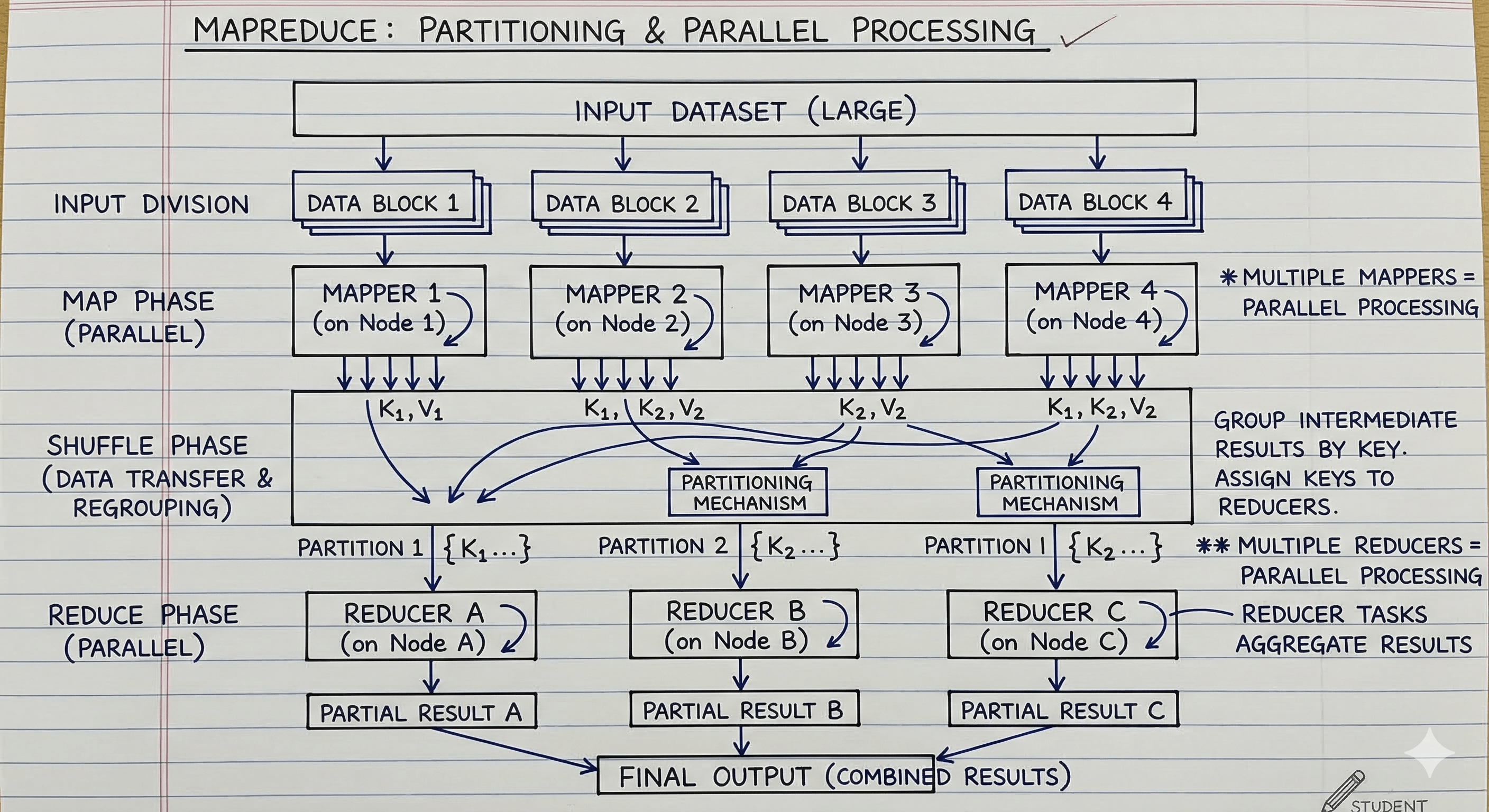
During the shuffle phase, intermediate key–value pairs generated by the map tasks are grouped by key. A partitioning mechanism determines which reducer will process each key. Each reducer receives only the keys assigned to its partition.
Because many mappers and reducers operate simultaneously across multiple machines, the system can process massive datasets in parallel.
Role of Combiner
A combiner acts as a local reducer that runs after the map phase but before the shuffle stage. Its purpose is to reduce the amount of intermediate data that must be transferred across the network.
For example, if a mapper produces many (word, 1) pairs for the same word, the combiner can locally aggregate them into a smaller number of intermediate results such as (word, 50). This reduces network traffic and improves system efficiency.

Role of Partitioner
The partitioner determines which reducer should receive a given key. It typically uses a hashing function or key-based routing mechanism.

For example:
partition = hash(key) % number_of_reducers
This ensures that:
- all records with the same key are sent to the same reducer
- workload is distributed evenly across reducers
- parallel processing is maintained
Assumptions about data distribution
The implementation assumes that:
- input data is distributed across multiple nodes in a distributed storage system
- map tasks operate independently on different data blocks
- reducers receive grouped intermediate key–value pairs
- nodes in the cluster communicate to transfer intermediate data during the shuffle phase
Under this architecture, large datasets can be processed efficiently because the computation is distributed across many machines rather than executed on a single system.
Overall MapReduce workflow
The overall workflow can be summarized as:
Input Data
→ Data Split into Blocks
→ Parallel Map Tasks
→ Shuffle and Sort Intermediate Results
→ Reduce Tasks Aggregate Results
→ Final Output Generated

This distributed processing pattern enables scalable analysis of very large datasets by leveraging parallel computation across multiple machines.
Scenario 7
Content Delivery Networks (CDNs) are widely used to deliver large volumes of internet content such as video streaming, software downloads, and web assets.
- Discuss how CDNs improve performance and scalability for global internet services.
- Explain how caching at geographically distributed edge locations reduces latency and network congestion.
- Illustrate your explanation with an example involving a user requesting a video from a distant data centre.
[5 Marks]
Introduction to Content Delivery Networks (CDNs)
A Content Delivery Network (CDN) is a distributed system of servers deployed across multiple geographic locations to deliver internet content efficiently to users. Instead of relying on a single central server to handle all requests, CDNs distribute content across multiple edge servers placed closer to end users. When a user requests content, the request is served from the nearest edge location whenever possible, improving performance and reducing response time.

Improving Performance and Scalability
CDNs improve performance by reducing the physical distance that data must travel between the server and the user. When content is served from nearby edge servers, latency decreases and users experience faster loading times.
CDNs also improve scalability by distributing incoming traffic across many servers rather than concentrating requests on a single origin server. If a large number of users request the same content simultaneously, the CDN infrastructure can handle the traffic by serving requests from multiple edge nodes. This prevents the origin server from becoming overloaded and allows the system to support very large numbers of users.
Role of Geographically Distributed Caching
One of the key mechanisms used by CDNs is caching. Frequently requested content such as images, videos, and web assets is temporarily stored in edge servers located around the world.
When a user requests content, the CDN performs the following steps:
- The request is routed to the nearest edge server.
- The edge server checks whether the requested content is already stored in its cache.
- If the content exists in the cache, it is delivered directly to the user.
- If the content is not cached, the CDN retrieves it from the origin server and stores it locally for future requests.

This caching strategy reduces the number of requests that must travel to the origin server and significantly reduces network congestion.
Example Scenario: Global Video Delivery
Consider a situation where a company stores video content on a server located in London. If a user in Sydney requests a popular video, the first request may retrieve the video from the London server. Once the video is delivered, the CDN stores a cached copy of the video at an edge server located in Sydney.
When other users in Australia request the same video, the CDN serves the video directly from the Sydney edge server instead of fetching it again from London. This reduces long-distance data transfers, lowers latency, and provides faster video playback for users in that region.

Conclusion
Content Delivery Networks improve internet service performance by reducing latency, distributing traffic across multiple servers, and caching frequently accessed content near users. By delivering content from geographically distributed edge locations, CDNs enable systems to handle large volumes of traffic efficiently while maintaining fast response times and reliable service delivery.
Scenario 8
Modern distributed applications often rely on scalable messaging systems to handle high-volume data streams generated by users, sensors, and applications.
Design a scalable messaging architecture using a publish–subscribe model similar to Kafka.
Your design should include:
- producers generating messages
- topics organising message streams
- partitions enabling parallel processing
- brokers storing and distributing partitions
- consumers processing incoming messages
Explain:
- How partitioning enables parallelism and high throughput
- How replication improves availability and fault tolerance
- How producer keys influence partition routing and ordering guarantees
- How such an architecture supports large-scale real-time data processing applications
Discuss potential challenges such as message ordering, partition balancing, and system failure handling.
[13 Marks]
Introduction to Scalable Messaging Architecture
Modern distributed systems often need to process extremely large volumes of data generated by applications, sensors, and user interactions. A scalable messaging architecture based on the publish–subscribe model enables efficient communication between different components of the system. In this model, producers publish messages to a messaging system, and consumers subscribe to receive and process those messages. The architecture is designed to handle high-throughput data streams while maintaining reliability and scalability.
Components of the Messaging Architecture
A scalable messaging architecture consists of several key components that work together to manage message flow and processing.

Producers
Producers are applications or services that generate messages and send them to the messaging system. These messages may represent events such as user actions, sensor readings, transactions, or system logs. Producers publish records to specific topics within the messaging system.
Topics
A topic is a logical category or stream of messages. Messages belonging to the same type of event or data are grouped into topics. For example, an e-commerce system may have topics such as orders, payments, and user activity. Applications publish messages to topics and consumers subscribe to topics to process the incoming data.
Partitions
Each topic can be divided into multiple partitions. Partitioning allows data within a topic to be split across multiple nodes so that messages can be processed in parallel. Each partition maintains an ordered sequence of messages. Because partitions operate independently, multiple consumers can process messages simultaneously, enabling high throughput and scalability.
Brokers
Brokers are servers responsible for storing topic partitions and serving read and write requests from producers and consumers. A messaging cluster consists of multiple brokers that collectively store and manage the partitions. Distributing partitions across brokers spreads the storage and processing load across the cluster.
Consumers
Consumers are applications that subscribe to topics and process incoming messages. Multiple consumer instances can read messages from different partitions in parallel. This parallel consumption allows the system to process large streams of data efficiently.

How Partitioning Enables Parallelism and High Throughput
Partitioning divides a topic into multiple independent partitions. Each partition can be processed by a separate consumer instance. Because partitions operate independently, multiple consumers can process messages simultaneously.
For example, if a topic contains four partitions, four consumers can process the partitions in parallel. This parallelism significantly increases system throughput and enables the architecture to handle very large data streams.
How Replication Improves Availability and Fault Tolerance
Replication creates multiple copies of each partition across different brokers in the cluster. If one broker fails, another broker that holds a replica of the partition can continue serving data.
This mechanism ensures that messages are not lost and that the system continues operating even when hardware failures occur. Replication therefore improves both system reliability and availability.
Influence of Producer Keys on Partition Routing and Ordering
Producers may include a key with each message. The messaging system uses the key to determine which partition the message should be stored in. Messages with the same key are routed to the same partition.
This ensures that all messages associated with the same key maintain their relative order within that partition. For example, all events related to a particular user ID may be routed to the same partition so that the sequence of events for that user remains consistent.
Support for Large-Scale Real-Time Data Processing
This messaging architecture supports real-time data processing by enabling producers to continuously publish messages while consumers process them asynchronously. Because data streams are partitioned and distributed across multiple brokers and consumers, the system can process extremely large volumes of data in real time.
Applications such as transaction monitoring, clickstream analysis, fraud detection, and IoT data processing rely on such architectures to handle continuous data streams at scale.
Challenges in Messaging System Architecture
Although scalable messaging systems provide many benefits, several challenges must be addressed.
Message ordering: Ordering is guaranteed only within individual partitions, not across the entire topic.
Partition balancing: Uneven distribution of messages across partitions may cause some partitions to receive heavier workloads than others.
System failure handling: Broker failures, network issues, or consumer crashes must be managed through replication, monitoring, and automatic recovery mechanisms.
Conclusion
A publish–subscribe messaging architecture using producers, topics, partitions, brokers, and consumers enables distributed systems to handle high-volume data streams efficiently. Partitioning allows parallel processing, replication ensures reliability, and key-based routing preserves ordering where necessary. This architecture forms the foundation for many modern real-time data processing systems operating at large scale.
Scenario 9
A global online ticketing platform experiences sudden spikes in traffic when popular concerts or sporting events go on sale. During peak demand, millions of users attempt to purchase tickets simultaneously, causing system slowdowns and occasional failures.
a) Explain how service replication can improve the system’s ability to handle high transaction volumes.
b) Describe the role of load balancing in distributing incoming ticket purchase requests across replicated services.
c) Discuss the difference between stateless and stateful service replicas and explain which model would be easier to scale in this scenario.
d) Design a scalable architecture that ensures high availability and stable performance during extreme traffic spikes. Your design should include service replication, load balancing, and caching mechanisms.
[3 + 2 + 2 + 5 = 12 Marks]
Service Replication for Handling High Transaction Volumes
Service replication involves running multiple instances of the same service so that incoming requests can be processed by several servers simultaneously. Instead of a single service instance handling all ticket purchase requests, multiple replicas of the service are deployed across different servers.

This approach increases the system’s ability to process a large number of transactions because requests are handled in parallel by multiple service instances. Replication also improves system availability because if one replica fails, other replicas can continue processing requests without interrupting the overall service.
In the context of an online ticketing platform experiencing traffic spikes, service replication ensures that the system can handle a large number of concurrent purchase requests while maintaining acceptable response times.
Role of Load Balancing
Load balancing distributes incoming client requests across multiple service replicas. A load balancer acts as an entry point for user requests and determines which replica should handle each request.
By distributing requests across multiple servers, load balancing prevents any single server from becoming overloaded. It also improves system stability because traffic can be redirected to healthy servers if one instance becomes unavailable.
Common load balancing strategies include:
- Round-robin routing, where requests are distributed sequentially across replicas
- Least-connections routing, where traffic is directed to the server with the fewest active connections
- Health-based routing, where requests are sent only to servers that pass health checks
These mechanisms ensure efficient resource utilisation and maintain consistent response times during traffic surges.
Stateless vs Stateful Service Replicas
Stateless services do not store session or user-specific information within the service instance. Each request contains all the information required for processing. Because there is no internal state to synchronize between replicas, stateless services can be replicated easily and scaled horizontally.
Stateful services maintain internal state information such as user sessions, transaction data, or application context. When stateful services are replicated, the state must be synchronized across replicas to maintain consistency. This introduces additional complexity and coordination overhead.
For the online ticketing system, stateless service replicas are easier to scale because new instances can be added quickly without requiring synchronization of internal state between servers.
Scalable Architecture for High Traffic Events
A scalable architecture for handling extreme traffic spikes would include several components working together to distribute workload and maintain system stability.
At the entry point, a load balancer receives incoming user requests and distributes them across multiple application servers. Behind the load balancer, multiple replicated service instances process ticket purchase requests in parallel.
To reduce repeated database access, a caching layer can store frequently accessed data such as event details, seat availability snapshots, or pricing information. This reduces the number of queries sent to the primary database and improves response time.
The backend database layer can be replicated or partitioned to handle increased read and write operations. If one service replica fails, the load balancer automatically redirects traffic to the remaining healthy instances.

This architecture ensures that during extreme traffic spikes:
- incoming requests are distributed across multiple service replicas
- database load is reduced through caching
- failures of individual servers do not interrupt the overall service
By combining service replication, load balancing, and caching, the system can maintain high availability and stable performance even during sudden surges in user demand.
Scenario 10
A financial analytics company processes millions of real-time transaction events from payment systems worldwide. The system must handle high throughput while ensuring resilience and decoupling between services.
Input Components:
- Multiple producers generating transaction events
- A message broker handling event distribution
- Worker services that analyse and process the transactions
Output:
- Processed transaction insights and alerts generated in real time
Using your understanding of asynchronous communication and messaging systems, develop a Python-style pseudocode implementation of a simplified event processing system using a message broker.
Your answer should include:
- a producer component that publishes transaction events
- a broker or queue abstraction that stores events
- a consumer component that processes events
- explanation of how asynchronous communication improves throughput and resilience
Also explain how message brokers help with load leveling during traffic spikes. [10 Marks]
Introduction
In large-scale financial systems, millions of transaction events may be generated continuously by payment gateways, mobile applications, and banking services. Processing these events synchronously would create bottlenecks because each system component would need to wait for responses from other services. An asynchronous event-driven architecture using a message broker allows producers and consumers to operate independently, enabling high throughput and improved system resilience.
Producer Component
The producer generates transaction events and sends them to the messaging system. Producers do not need to know which service will process the message; they only publish the event to the broker.
def producer(transaction_event): broker.publish("transactions_topic", transaction_event)
Each transaction event may contain details such as transaction ID, user ID, payment amount, and timestamp.
Message Broker / Queue Abstraction
The message broker temporarily stores messages and ensures they are delivered to consumers. It acts as an intermediary between producers and consumers.
class MessageBroker: def __init__(self): self.queue = [] def publish(self, topic, message): self.queue.append((topic, message)) def consume(self): if self.queue: return self.queue.pop(0) return None
The broker buffers incoming events and distributes them to available consumers.
Consumer Component
Consumers subscribe to the topic and process transaction events independently. Multiple consumer instances can run simultaneously to increase processing capacity.
def consumer(): while True: event = broker.consume() if event is not None: topic, message = event process_transaction(message)
Each consumer processes events such as fraud detection, transaction validation, or analytics generation.
How Asynchronous Communication Improves Throughput and Resilience
In an asynchronous system, producers send messages without waiting for immediate responses from consumers. The producer simply publishes the event to the broker and continues processing other requests.
This approach improves throughput because:
- producers do not block waiting for processing to complete
- consumers process messages independently
- multiple consumers can process messages in parallel
Resilience is improved because if one consumer fails, the broker still retains the message and another consumer can process it. This prevents data loss and ensures system reliability.
Role of Message Brokers in Load Leveling
Message brokers help manage sudden spikes in incoming traffic by acting as a buffer between producers and consumers.
If transaction events arrive faster than they can be processed, the broker temporarily stores them in the queue. Consumers then process the events gradually as resources become available.
This mechanism prevents system overload and ensures that high traffic bursts do not cause service failures. Instead of overwhelming downstream services, the broker smooths the workload and maintains stable system performance.
Conclusion
An asynchronous event processing architecture using a message broker enables scalable transaction processing in distributed systems. Producers generate events independently, the broker buffers and distributes messages, and multiple consumers process events in parallel. This design increases system throughput, improves fault tolerance, and allows the system to handle large volumes of transaction events efficiently.
Scenario 11
Modern microservice architectures often use synchronous and asynchronous communication protocols for service interaction.
Discuss the differences between synchronous and asynchronous communication models in distributed systems. Explain how asynchronous communication improves system scalability and resilience. Provide examples of scenarios where each communication model would be appropriate.
[5 Marks]
Introduction
In distributed systems and microservice architectures, services must communicate with each other to perform operations such as processing transactions, retrieving data, or triggering business workflows. Two common communication models used for service interaction are synchronous communication and asynchronous communication. These models differ in how services exchange information and how tightly they depend on each other during processing.
Synchronous Communication
In synchronous communication, a service sends a request to another service and waits for a response before continuing its execution. The calling service remains blocked until the requested service processes the request and returns the result.
This communication model follows a request–response pattern, which is commonly used in APIs and web services. For example, when a client application sends an HTTP request to a payment service, the application waits for confirmation that the transaction has been completed before proceeding.
While synchronous communication is simple and easy to implement, it introduces strong coupling between services. If the downstream service becomes slow or unavailable, the calling service must wait, which can increase latency and reduce system throughput.
Asynchronous Communication
In asynchronous communication, a service sends a message or event to another service without waiting for an immediate response. Instead of direct request–response interaction, messages are typically sent through a messaging system or broker.
The sending service continues executing other tasks while the receiving service processes the message independently. Because services do not wait for each other, asynchronous communication improves system scalability and overall throughput.
This approach also increases resilience. If a receiving service temporarily fails, messages can remain in the queue until the service becomes available again.
Scalability and Resilience Benefits of Asynchronous Communication
Asynchronous communication improves scalability because services operate independently and do not block each other. Multiple consumers can process messages in parallel, allowing the system to handle large volumes of events efficiently.
It also improves resilience because failures in one service do not immediately propagate to others. Messages can be buffered and processed later, preventing system-wide disruptions.
In high-traffic systems, asynchronous communication enables better load management because message queues can absorb bursts of incoming requests.
Appropriate Use Cases for Each Communication Model
Synchronous communication is suitable when immediate responses are required and the interaction must complete within a single request cycle. Examples include retrieving account details, validating login credentials, or checking inventory availability during a purchase.
Asynchronous communication is more suitable for background processing and event-driven workflows. Examples include order processing pipelines, sending email notifications, updating analytics systems, or processing IoT sensor data streams.
Conclusion
Both synchronous and asynchronous communication models play important roles in distributed system design. Synchronous communication provides simplicity and immediate responses, while asynchronous communication improves scalability, resilience, and system throughput. Choosing the appropriate communication model depends on the application requirements and the level of decoupling needed between services.
Scenario 12
A global video streaming platform must dynamically scale its infrastructure to handle highly variable traffic patterns. For example, during the release of a popular movie or sporting event, user demand may increase dramatically within minutes.
Design a scalable cloud architecture that incorporates:
- horizontal scaling of service instances
- load balancing across servers
- automatic scaling policies
- distributed caching
Explain:
- How auto-scaling mechanisms detect and respond to changes in system load
- How scaling metrics such as CPU utilization, request rate, or queue depth influence scaling decisions
- How cooldown periods and scaling policies help maintain system stability
- How the architecture achieves elasticity while balancing performance and cost
Discuss potential challenges such as over-scaling, delayed scaling reactions, and infrastructure cost management. [13 Marks]
Introduction
A global video streaming platform experiences highly variable traffic patterns. During major events such as the release of a new movie or a live sports broadcast, millions of users may access the platform simultaneously. To maintain stable performance under such conditions, the system must dynamically adjust its infrastructure capacity. A scalable cloud architecture can achieve this by combining horizontal scaling, load balancing, auto-scaling mechanisms, and distributed caching.
Scalable Architecture Design
The architecture consists of several layers that work together to manage traffic and processing demand.
At the entry point, a load balancer receives incoming user requests and distributes them across multiple application servers. These application servers are deployed as replicated instances so that requests can be processed in parallel.
Behind the application layer, a distributed cache stores frequently accessed content such as video metadata, recommendations, and user session information. By serving repeated requests directly from memory, the cache reduces the load on the backend database.

The system runs on cloud infrastructure where application instances are automatically scaled based on workload metrics. When traffic increases, new instances are launched to handle additional requests. When demand decreases, unnecessary instances are removed to reduce infrastructure cost.
Auto-Scaling Detection and Response
Auto-scaling systems continuously monitor system performance metrics to determine when scaling actions are required. Monitoring components collect data such as CPU utilization, request rates, or queue lengths.
When these metrics exceed predefined thresholds, the auto-scaling system automatically increases the number of service instances. This process is known as scaling out. When the workload decreases and system utilization falls below a threshold, the system reduces the number of running instances through scaling in.
This automated mechanism ensures that the system maintains stable performance even during sudden increases in demand.
Scaling Metrics and Decision Making
Scaling decisions are typically triggered by specific performance indicators.
CPU utilization is commonly used to detect when servers are approaching capacity limits. When CPU usage exceeds a defined threshold, additional instances are launched.
Request rate measures the number of incoming requests per second. If request traffic increases rapidly, the system can add more servers before CPU usage becomes a bottleneck.
Queue depth is another important metric, especially for background processing systems. If the queue length increases, additional worker instances can be deployed to process pending tasks.
These metrics allow the system to detect workload changes and respond accordingly.
Role of Cooldown Periods and Scaling Policies
Scaling policies define how the system responds to changes in workload. A common approach is target tracking, where the auto-scaling system attempts to maintain a specific resource utilization level, such as 60 percent CPU usage.
Cooldown periods are used to prevent unstable scaling behaviour. After a scaling action occurs, the system waits for a defined time before evaluating whether additional scaling is necessary. This prevents rapid fluctuations in the number of instances due to temporary spikes in traffic.
These mechanisms ensure that scaling actions occur gradually and maintain system stability.
Achieving Elasticity While Balancing Cost and Performance
Elasticity refers to the ability of a system to automatically increase or decrease its infrastructure capacity based on actual demand. During high traffic periods, additional servers are launched to maintain performance. When traffic decreases, unnecessary servers are removed to reduce operational cost.
By dynamically adjusting infrastructure capacity, the platform avoids the need to permanently provision resources for peak demand. This ensures that the system remains cost-efficient while still providing reliable performance during high traffic events.
Potential Challenges
Although auto-scaling systems provide significant benefits, several challenges must be managed.
Over-scaling may occur if scaling thresholds are configured too aggressively, resulting in unnecessary infrastructure costs.
Delayed scaling reactions may occur if monitoring systems detect traffic spikes too late.
Infrastructure cost management becomes important when large numbers of instances are running during peak demand periods.
Careful configuration of scaling policies and monitoring metrics is therefore essential to maintain an optimal balance between performance and cost.
Conclusion
A scalable cloud architecture combining horizontal scaling, load balancing, distributed caching, and auto-scaling mechanisms allows a video streaming platform to handle unpredictable traffic patterns effectively. By monitoring system metrics and dynamically adjusting infrastructure capacity, the system maintains stable performance during demand spikes while controlling operational costs during normal traffic conditions.
Scenario 13
A large online retail company runs a microservices-based application where multiple services communicate with each other to process customer orders, payments, and inventory updates. During peak shopping seasons, the synchronous communication between services begins to create delays and cascading failures when downstream services respond slowly.
a) Explain how asynchronous communication using message brokers can improve system resilience and throughput in this scenario.
b) Describe the role of a message broker in decoupling producers and consumers within a distributed system.
c) Compare Kafka and RabbitMQ in terms of message retention and typical use cases.
d) Design an event-driven architecture for this retail platform using a message broker, ensuring that order processing, payment validation, and inventory updates can scale independently.
[3 + 2 + 2 + 5 = 12 Marks]
Introduction
In large microservice-based systems such as online retail platforms, different services handle specific business functions such as order processing, payment validation, and inventory management. When these services communicate synchronously, delays in one service can propagate to others, causing cascading failures and reduced system performance. An asynchronous event-driven architecture using message brokers allows services to communicate through events without waiting for immediate responses, improving scalability and resilience.
Asynchronous Communication Using Message Brokers
In an asynchronous communication model, services send messages or events to a messaging system instead of directly invoking other services. The sending service does not wait for the receiving service to complete its work. Instead, messages are stored in a broker or queue and processed by consumer services when resources are available.
This model improves throughput because services can continue processing new requests while background services handle previously generated events. It also improves resilience because temporary failures in one service do not immediately affect other services.
For example, when a customer places an order, the order service can publish an event such as OrderCreated to a message broker. Other services such as payment processing and inventory management can consume this event and perform their tasks independently.
Role of a Message Broker
A message broker acts as an intermediary between producers and consumers in a distributed system. It receives messages from producers, stores them temporarily, and forwards them to consumers.
The broker enables several important functions:
- Decoupling of services, since producers and consumers do not communicate directly
- Load leveling, by buffering messages during traffic spikes
- Asynchronous processing, allowing services to process events independently
By separating message production from message consumption, the broker allows services to scale independently and operate more reliably under heavy workloads.
Comparison of Kafka and RabbitMQ
Kafka and RabbitMQ are widely used messaging platforms but serve different purposes.
Kafka is designed for high-throughput event streaming systems. It stores messages in persistent logs and retains them for a configurable period of time. This allows consumers to replay events and process historical data streams. Kafka is commonly used for event streaming, analytics pipelines, and activity tracking systems.

RabbitMQ is designed primarily for task distribution and message queuing. Messages are routed through exchanges into queues and delivered to worker services. Once a message is acknowledged by a consumer, it is removed from the queue. RabbitMQ is well suited for background job processing, notification systems, and task scheduling.

Conceptual Difference

Event-Driven Architecture Design
A scalable event-driven architecture for the retail platform can be structured as follows.
At the entry point, an order service receives customer purchase requests. When an order is created, the service publishes an event to a message broker.
The message broker distributes this event to multiple consumer services:
- Payment service processes payment transactions
- Inventory service updates product availability
- Notification service sends confirmation messages to the customer
Each service processes the event independently without direct interaction with other services. If demand increases, additional instances of each service can be deployed to process events in parallel.

This architecture improves scalability because services can be scaled independently. It also improves reliability because failures in one service do not interrupt the entire order processing workflow.
Conclusion
An event-driven architecture using message brokers enables scalable and resilient communication in microservice systems. By decoupling producers and consumers, buffering messages during traffic spikes, and allowing independent service scaling, asynchronous messaging systems ensure that high-demand retail platforms can process large volumes of transactions reliably.
Scenario 14
An IoT platform collects telemetry data from millions of sensors deployed in industrial environments. Sensor readings arrive continuously and must be analysed in real time to detect anomalies and trigger alerts.
Input Components:
- Sensors producing telemetry data
- A streaming ingestion service receiving events
- A processing system performing analytics
- A storage system recording processed data
Output:
- Real-time alerts and analytics results
Using your understanding of scalable event-driven architectures, develop a Python-style pseudocode implementation that illustrates how an event-driven system can process sensor data.
Your answer should include:
- an event producer representing IoT sensors
- an event queue or streaming platform handling incoming data
- an event processor performing anomaly detection
- explanation of how asynchronous processing improves scalability and fault tolerance
Also explain how buffering and queueing help manage bursts of incoming sensor data.
[10 Marks]
Introduction
In an Internet of Things (IoT) environment, millions of sensors continuously generate telemetry data such as temperature, pressure, vibration, or energy consumption readings. Processing these data streams using synchronous architectures would quickly create performance bottlenecks. An event-driven architecture allows sensor data to be processed asynchronously using message queues or streaming platforms, enabling the system to scale horizontally and handle very large volumes of incoming data.
Event Producer (IoT Sensors)
Sensors act as event producers that generate telemetry readings at regular intervals. Each reading is sent to an ingestion service or message broker as an event.
def sensor_producer(sensor_id, reading): event = { "sensor_id": sensor_id, "value": reading, "timestamp": current_time() } event_stream.publish("sensor_topic", event)
Each event typically contains the sensor identifier, the measured value, and the timestamp at which the reading was generated.
Event Queue / Streaming Platform
The event queue or streaming platform receives incoming sensor events and temporarily stores them before distributing them to processing services.
class EventStream: def __init__(self): self.queue = [] def publish(self, topic, event): self.queue.append(event) def consume(self): if self.queue: return self.queue.pop(0)
This component acts as a buffer between producers and processors, preventing downstream services from being overwhelmed during periods of high data ingestion.
Event Processor (Analytics Engine)
Processing services consume events from the queue and analyse the incoming sensor data. These services may perform tasks such as anomaly detection, trend analysis, or alert generation.
def event_processor(): while True: event = event_stream.consume() if event is not None: if detect_anomaly(event["value"]): trigger_alert(event)
Multiple processing services can run simultaneously, allowing events to be processed in parallel.
How Asynchronous Processing Improves Scalability and Fault Tolerance
In an asynchronous architecture, producers and consumers operate independently. Sensors can continue sending data without waiting for the analytics system to process previous events.
This design improves scalability because:
- multiple processors can handle events in parallel
- processing capacity can be increased by adding more worker nodes
- the system avoids blocking delays between services
Fault tolerance is also improved. If a processing node fails, the events remain in the queue and can be processed by other available nodes once they recover.
Role of Buffering and Queueing in Managing Traffic Bursts
Sensor networks often generate uneven traffic patterns. During peak periods, the number of incoming events may exceed the processing capacity of the analytics system.
Queueing mechanisms allow the system to temporarily store these events. The queue absorbs the burst of incoming data and releases events to processing services at a manageable rate.
This technique, known as load leveling, prevents the analytics system from being overloaded and ensures stable system performance even during sudden spikes in data generation.
Conclusion
An event-driven architecture using event producers, message queues, and distributed processing services enables scalable and resilient processing of IoT sensor data. Asynchronous communication allows the system to handle large volumes of events efficiently, while buffering and queueing mechanisms ensure stable operation during bursts of incoming data.
Scenario 15
A cloud-based application experiences frequent database overload due to repeated requests for the same data. Engineers decide to introduce caching to improve system performance.
Discuss the concept of caching in distributed systems and explain how caching improves response time and reduces database load. Compare local caching and distributed caching approaches and discuss scenarios where a distributed cache would be more suitable.
[5 Marks]
Introduction
Caching is a technique used in distributed systems to store frequently accessed data in a temporary storage layer that provides faster access than the primary data source. Instead of repeatedly retrieving the same data from a database or remote service, the system stores a copy of that data in memory so that future requests can be served quickly. This approach significantly improves application performance and reduces the load on backend systems.
How Caching Improves Performance and Reduces Database Load
In many cloud applications, users frequently request the same information, such as product details, user profiles, configuration data, or frequently viewed content. Without caching, every request must be processed by the database, which increases latency and places heavy demand on database resources.
Caching improves system performance in several ways:
First, it reduces response time because data stored in memory can be retrieved much faster than data stored in disk-based databases.
Second, it reduces database workload because repeated queries are served directly from the cache rather than from the database.
Third, it improves system scalability because the backend database receives fewer requests, allowing the system to support a larger number of concurrent users.
For example, in an e-commerce application, product details that are frequently viewed by users can be stored in a cache. When users request this information, the system retrieves it from the cache instead of executing a database query each time.
Local Caching
Local caching stores frequently accessed data within the memory of the application server itself. Each server maintains its own cache, allowing it to quickly retrieve data without contacting external services.
Advantages of local caching include:
- extremely fast data access because the cache is stored in the same process memory
- minimal network latency because the data does not need to travel across the network
However, local caching also has limitations. Because each server maintains its own cache, data stored in one server’s cache may not be available to other servers. This can lead to cache inconsistency, where different servers hold different versions of the same data.
Local caching is often suitable for small applications or systems where each server processes independent workloads.
Distributed Caching
Distributed caching stores cached data across multiple dedicated cache servers that are accessible by all application instances. Instead of maintaining separate caches for each server, the application communicates with a shared caching layer.
Examples of distributed caching systems include Redis, Memcached, and cloud-managed caching services.
Distributed caching provides several advantages:
- all application servers access the same cache layer
- data consistency across multiple servers is easier to maintain
- the cache can scale horizontally by adding additional cache nodes
Because distributed caching systems operate across multiple machines, they can store larger datasets and support higher traffic volumes than local caches.
When Distributed Caching is More Suitable
Distributed caching is more appropriate in environments where applications are deployed across multiple servers or microservices. In such systems, maintaining a shared cache ensures that all services retrieve the same data and benefit from cached results.
For example, in a large web application running across many application servers behind a load balancer, a distributed cache allows all servers to access the same cached product data or session information. This prevents redundant database queries and improves system performance across the entire application cluster.
Conclusion
Caching plays a critical role in improving the performance and scalability of distributed systems. By storing frequently accessed data in memory, caching reduces database load and accelerates response times. Local caching provides extremely fast access for single-server environments, while distributed caching enables shared data access and scalability across multiple servers in large distributed applications.
Scenario 16
A global media company operates a large-scale cloud platform that must handle unpredictable spikes in user demand. Traffic varies significantly throughout the day, with sudden surges during major events or new content releases.
Design a scalable cloud architecture that uses auto-scaling, load balancing, and serverless computing to handle fluctuating workloads.
Explain:
- How auto-scaling mechanisms monitor system metrics and dynamically adjust capacity
- How load balancers distribute incoming traffic across multiple service instances
- How serverless computing supports event-driven workloads and dynamic scaling
- How the architecture maintains cost efficiency while ensuring high performance during peak demand
Discuss potential limitations of serverless architectures in high-throughput systems.
[13 Marks]
Introduction
Cloud applications often experience fluctuating workloads where the number of users and requests changes rapidly over time. For example, a media streaming platform may experience sudden spikes in demand when new content is released. To handle these variations efficiently, cloud systems use auto-scaling, load balancing, and serverless computing to dynamically adjust computing resources according to demand. This approach ensures that the system maintains high performance while controlling operational costs.
Auto-Scaling and Monitoring System Load
Auto-scaling mechanisms continuously monitor system performance metrics to determine whether additional computing resources are required. These metrics may include
- CPU utilisation
- request rate
- memory usage
- or queue length.
When the monitored metrics exceed predefined thresholds, the system automatically launches additional service instances to handle the increased workload. This process is known as horizontal scaling, where new instances are added rather than increasing the capacity of existing machines.
When demand decreases, the system removes unnecessary instances to reduce infrastructure costs. This dynamic adjustment allows the platform to maintain stable performance without permanently provisioning resources for peak demand.
Role of Load Balancers
Load balancers act as the entry point for incoming user requests. They distribute requests across multiple service instances to ensure that no single server becomes overloaded.
The load balancer continuously monitors the health and availability of service instances. If a server becomes unresponsive or fails, the load balancer automatically redirects traffic to other healthy instances.
By distributing traffic across multiple servers, load balancing improves system reliability, reduces response time, and ensures efficient utilisation of computing resources.
Serverless Computing for Event-Driven Workloads
Serverless computing allows developers to run application logic without managing servers directly. Instead of provisioning infrastructure, developers deploy small functions that are executed in response to events such as HTTP requests, file uploads, or database updates.
Serverless platforms automatically allocate computing resources when functions are invoked and release them once execution is complete. This model is highly suitable for workloads that occur intermittently or unpredictably.
Because serverless functions scale automatically based on the number of incoming events, they provide a highly elastic environment capable of handling sudden traffic spikes without manual intervention.
Achieving Elasticity and Cost Efficiency
Elasticity refers to the ability of a system to automatically expand or shrink its computing capacity in response to demand. During periods of high traffic, the system launches additional service instances or serverless executions to maintain performance.
When traffic decreases, unused resources are removed, ensuring that the organisation pays only for the infrastructure actually required. This pay-as-you-use model makes cloud systems both scalable and cost-efficient.
Potential Limitations of Serverless Architectures
Despite their advantages, serverless architectures may present certain limitations in high-throughput systems.
- Cold start latency: First, serverless functions may experience cold start latency when functions are invoked after periods of inactivity. This delay can affect response times for latency-sensitive applications.
- Limits on execution duration: Second, serverless platforms impose limits on execution duration, memory usage, and concurrent executions, which may restrict certain long-running or resource-intensive workloads.
- Complex Debugging: Third, debugging and monitoring distributed serverless systems can be more complex because execution environments are short-lived and highly dynamic.
Conclusion
By combining auto-scaling, load balancing, and serverless computing, cloud platforms can dynamically adapt to changing workloads and maintain reliable performance. Auto-scaling ensures that sufficient computing capacity is available during peak demand, load balancing distributes traffic efficiently across service instances, and serverless computing enables flexible event-driven processing. Together, these technologies enable cloud systems to achieve high scalability while maintaining cost efficiency.
2 Comments